25 Dec 2025
The biggest changes for me in 2025 were:
- Health: I was diagnosed as pre-diabetic. In response, I increased the amount of vegetables in my diet and drastically reduced the amount of sugars and carbohydrates. As a result, I lost 30 pounds, and my pre-diabetes is in remission. So far so good!
- AI Agents: I started the year by copying-and-pasting code into chatbots. Then I wrote my own primitive agents that called LLM APIs. By the end of the year I was heavily using commercial agents.
As I write this in late December, I find myself cycling between Antigravity, Gemini CLI, Jules, and several internal-to-my-company agents. Each one has its strengths. All of them regularly receive boosts in performance as better prompts and better base models are introduced.
Advent of Code
This year I thoroughly investigated the ability of LLMs to solve Advent of Code puzzles.
At the beginning of the year, I had to write my own agentic harness to solve the Advent of Code puzzles. But over the year, the standard agents available to me started to support running tools and code. By the end of the year multiple agents were able to solve all the puzzles by themselves, with only a simple prompt that explained the rules of the contest. To minimize the load on the Advent of Code servers, I cached all the puzzle data locally.
| Agent |
Model |
Wall Time (minutes) |
Notes |
| Antigravity |
gemini-3-flash-preview |
32 |
Had to be encouraged to continue. Struggled to solve 2025-10-2, but eventually got it. |
| Gemini CLI |
gemini-3-flash-preview |
13 |
One shot solved all the puzzles. |
| Jules |
Gemini 3 |
40 |
Had to be encouraged to continue. |
That level of performance means that Advent of Code is “saturated” as a benchmark. All the agents can solve all the problems using a wide variety of base models and implementation languages. The only topic left to explore is the agents’ ability to navigate the Advent of Code website and create their own contest accounts. I have no doubt several agents could accomplish that, but it’s orthogonal to solving the actual puzzles. And I don’t want to bother the Advent of Code website with synthetic activity.
Programming Languages
Because of the power, speed, and flexibility of agents, I find myself using English as my programming language. I direct the LLMs to use whatever implementation language is appropriate for the task. This year I vibe-coded the most in Python, but for many tasks I’m starting to shift towards more strongly-typed languages like Go and Rust. In my experience, strongly-typed languages reduce the number of rounds of debugging required to implement features.
Looking forward to 2026
I expect the performance of LLMs and agents to keep improving.
I hope to keep improving my ability to use LLMs and agents to solve interesting problems.
Best wishes to you and your family for a happy and prosperous 2026!
06 Jul 2025
A few weeks ago, my TabloTV, which I use to record over-the-air TV, started making strange noises. I could hear the hard drive seeking constantly and a separate chirping sound. Eventually, it failed completely. The UI showed a “No Storage” error, and I couldn’t watch any of my recordings.
Here’s how I diagnosed and fixed the problems.
Problem 1: The “No Storage” Error
My first goal was to get my recordings back. TabloTV’s support suggested I replace the hard drive, but I wanted to see if I could repair it first. I learned from the TabloTV forums that the device uses the ext4 filesystem, and that other people had been able to fix this issue by attaching their TabloTV’s drive to a Linux PC and using the fsck command to repair the filesystem.
I don’t have a general-purpose Linux PC at home. But I do have a Mac. I used UTM to run an Ubuntu Server virtual machine on my Mac. I enabled USB sharing in UTM, which let the VM see the TabloTV’s hard drive when I plugged it in.
Inside the VM, the drive appeared as /dev/sdb. I ran fsck to repair it:
I put the drive back into the TabloTV, and it worked. The “No Storage” error was gone, and my recordings were accessible again. However, the drive was still making constant seeking noises.
Problem 2: Replacing the Hard Drive
It wasn’t clear whether the drive was failing or not. It seemed fine when accessed from the Linux VM. To rule out the possibility of a failing drive, I decided to replace the old 2TB spinning drive with a new 2TB SSD. To save my recordings, I needed to clone the old drive to the new one.
I first tried using rsync inside my Ubuntu VM to copy the files, but it was too slow, running at only 2.5 MB/s.
A full disk clone is much faster. I switched to a tool called ddrescue. To get the best performance, I installed ddrescue with Homebrew and ran it directly on my Mac, avoiding the VM overhead.
I used diskutil list to find the drive names. For my setup, the old drive was disk20 and the new SSD was disk21. I ran this command to clone the drive:
sudo ddrescue -f -v -c 262144 /dev/rdisk20 /dev/rdisk21 ddrescue.logfile
The cloning process took 36 hours. To prevent the Mac from sleeping, I used the caffeinate -is command. The whole disk copy completed with no errors. I installed the new SSD in the TabloTV. The seeking noises were gone, and the TabloTV’s UI felt faster.
Problem 3: The Chirping Noise
Even with the new, silent SSD, the TabloTV unit itself still made a high-pitched chirping sound.
I went back to the forums and found that a faulty power adapter can cause this. The original adapter was a 12V 2A model. I found a spare power adapter with the same specs from an old cable modem and swapped it in.
That fixed it. The chirping noise was gone.
Conclusion
My TabloTV had two problems: a corrupted filesystem and a bad power adapter. I fixed the filesystem with fsck and the noise by swapping the power adapter. I probably didn’t need to replace the hard drive, but the new SSD made the TabloTV silent and faster.
29 Mar 2025
The new Gemini 2.5 Pro model from Google is very good at solving Advent of Code 2024 puzzles using many different programming languages.
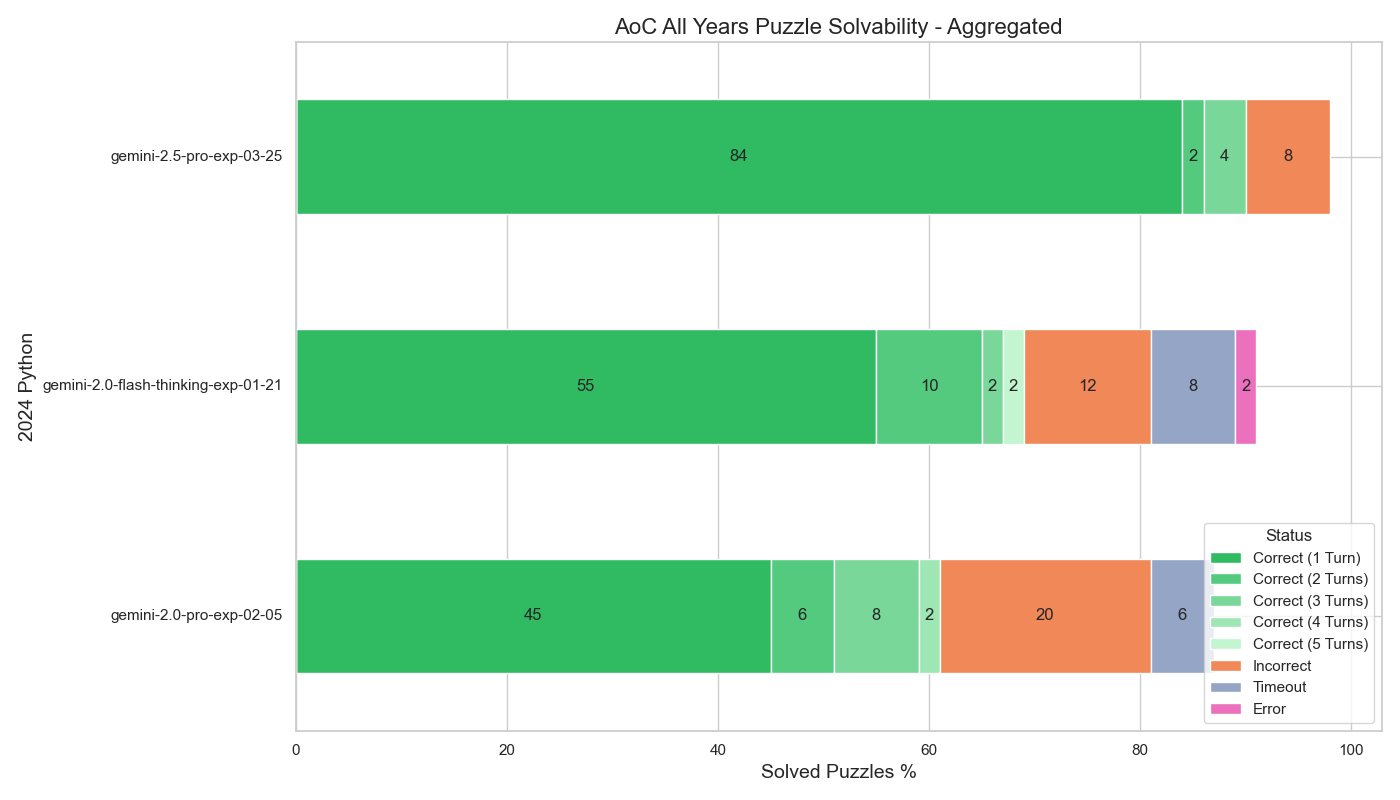
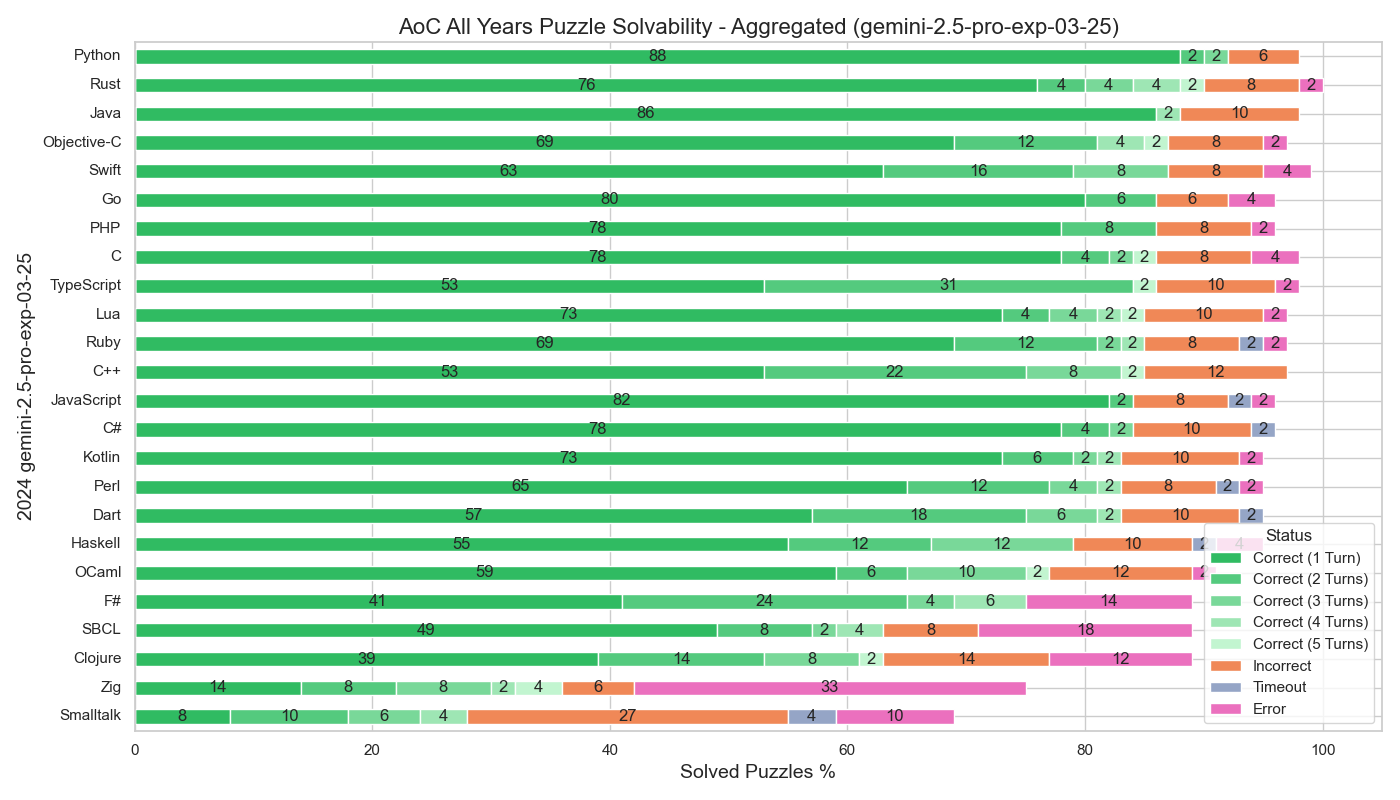
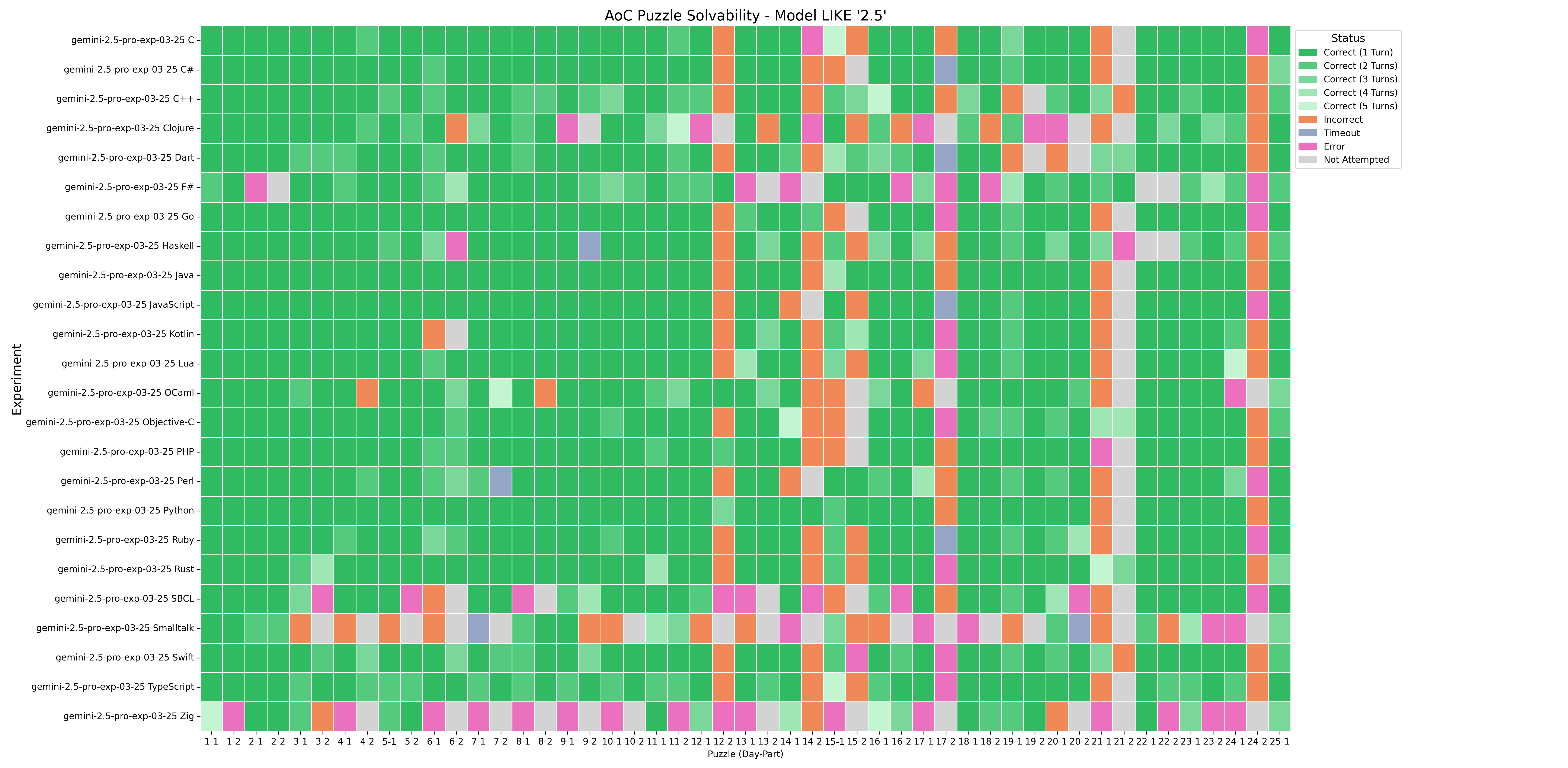
The puzzles that were difficult for Gemini 2.5 Pro were:
Day 12 Part 2: Garden Groups
This puzzle has a difficult to understand specification. It is easy to solve if you use the correct algorithm.
Day 14 Part 2: Restroom Redoubt
To solve this puzzle you have to either get lucky or reason from first principles. Gemini 2.5 did solve this one time, very cleanly.
Day 15: Warehouse Woes
This was a Sudoku-style sliding box simulation. Part 1 is easy to solve by using recursion, but difficult to solve using iteration. Gemini typically tries to solve using iteration. Gemini 2.5 Pro was the first Gemini model that I tested that was able to solve part 1 by implementing the able-to-push check recursively.
All Gemini models, including Gemini 2.5 Pro, had trouble with Part 2, as the rules for part 2 are assymetrical with respect to horizontal vs vertical movement.
Day 17 Part 2: Chronospatial Computer
Solving this requires examining the puzzle input and reasoning about it. Gemini was not presented with the puzzle input, so it could not reason about it. This was a limitation of the LLM evaluation setup, and was not a fair test of the model’s ability.
Day 21 Part 2: Keypad Conundrum
Solving part 2 in a reasonable time requires thinking at a higher level, not just brute-force simulating the puzzle.
Day 24 Part 2: Crossed Wires
Solving part 2 requires examining the puzzle input and reasoning about it. Gemini was not presented with the puzzle input, so it could not reason about it. This was a limitation of the LLM evaluation setup, and was not a fair test of the model’s ability.
Gemini 2.5 Pro performed best using Python. This is typical of LLMs, and it’s also reasonable due to Advent of Code being targeted towards Python programmers.
Gemini 2.5 Pro performed nearly as well on many other languages.
The languages it had trouble with were:
| Language |
Issues |
| Haskell |
Trouble using language extensions. |
| OCaml |
Trouble with library semantics |
| F# |
Trouble with language syntax, library semantics. |
| SBCL |
Trouble matching parens |
| Clojure |
Trouble matching parens, trouble with libraries. |
| Zig |
Trouble using type system, trouble reading error messages. |
| GNU Smalltalk |
Didn’t know the library. |
It is interesting to compare Rust to Zig performance. Rust is a difficult to use langauge, but there are a lot of examples on the web of Rust being used to solve coding puzzles.
It seems that Zig’s error reporting syntax, where errors are reported relative to the first line of the function rather than the first line of the source file, makes it hard for Gemini 2.5 to reason about the error messages.
More conversation turns would help
For many languages, we see that at least one puzzle was solved on the 5th turn of the conversation. That indicates that it is likely that the model could solve additional puzzles if given more converstation turns.
Possibility of memorization
Gemini 2.5 Pro’s knowledge cutoff is January 2025, which was after the Advent of Code 2024 contest was held. It is possible that information about the puzzles and their solutions was part of the training data for the model.
While it’s not possible to rule memorization out, there is not strong evidence in favor of memorization.
Links
Using Gemini to Solve Advent of Code 2024 Puzzles - a paper measuring how well Gemini 2.0 Flash Thinking solves Advent of Code 2024 puzzles.
07 Mar 2025
Here’s a handy utility I wrote. It walks a project source tree and creates a markdown file that contains all the project source code, with each file in a named code block.
Paste the result into a LLM chatbot system prompt. Then ask your questions.
This is better than manually pasting source code because it provides more context (such as the file names and directory structure).
And it’s better than most LLM Code IDE extensions because it sends all your source code at once, rather than just sending a few files. (Of course this only works with large-context LLMs like Gemini.)
source_tree_to_markdown.py
#!/usr/bin/env python3
import os
import argparse
LANG_MAPPING = {
".c": "c",
".cc": "cpp",
".cpp": "cpp",
".cs": "csharp",
".go": "go",
".h": "cpp",
".hpp": "cpp",
".html": "html",
".java": "java",
".js": "javascript",
".jsx": "javascript",
".kt": "kotlin",
".lua": "lua",
".m": "objectivec",
".md": "markdown",
".mm": "objectivec",
".php": "php",
".pl": "perl",
".py": "python",
".rb": "ruby",
".rs": "rust",
".sh": "shell",
".sql": "sql",
".swift": "swift",
".ts": "typescript",
".tsx": "typescript",
}
def create_system_prompt(root_dir, output_file, prompt_text):
"""
Generates a markdown document containing the names and content of source code files
in the specified root directory and its subdirectories, excluding directories starting with a period.
Args:
root_dir: The root directory to search for source code files.
output_file: The name of the output markdown file.
prompt_text: The introductory prompt text for the markdown file.
"""
with open(output_file, "w") as f:
f.write(f"{prompt_text}\n\n")
for root, dirs, files in os.walk(root_dir):
# Iterate in lexical order.
dirs.sort()
files.sort()
# Modify dirs in-place to prevent os.walk from recursing into directories starting with '.'.
# I'm looking at you, .git and .venv. Although, TBH .vscode might be handy to send.
dirs[:] = [d for d in dirs if not d.startswith(".")]
for filename in files:
_, ext = os.path.splitext(filename)
if ext in LANG_MAPPING:
filepath = os.path.join(root, filename)
relative_filepath = os.path.relpath(filepath, root_dir)
f.write(f"{relative_filepath}\n")
lang = LANG_MAPPING[ext]
# Markdown only requires 3 back-quotes. Using 5 back-quotes allows
# 3 back-quotes and 4 back-quotes to appear in the quoted document.
f.write(f"`````{lang}\n")
try:
with open(filepath, "r") as source_file:
f.write(source_file.read())
except UnicodeDecodeError:
f.write(
f"--- ERROR: Could not decode file content (non-text file?) ---\n"
)
except Exception as e:
f.write(f"--- ERROR: Could not read file content: {e} ---\n")
f.write("\n`````\n\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Create a system prompt for an LLM containing code from source files, excluding dot directories."
)
parser.add_argument(
"-o",
"--output",
default="initial_prompt.md",
help="The name of the output markdown file.",
)
parser.add_argument(
"-p",
"--prompt",
type=str,
default="Here are the sources to a project:",
help="The introductory prompt text.",
)
parser.add_argument(
"-r", "--root-dir", default=".", help="The root directory of the source code."
)
args = parser.parse_args()
root_dir = os.path.abspath(args.root_dir) # Ensure root_dir is absolute path
create_system_prompt(root_dir, args.output, args.prompt)
print(f"Project source code prompt written to {args.output}")
03 Feb 2025
The Advent of Code is a yearly programming contest made up of Christmas-themed puzzles designed to be solved using any programming language. I measured how well the gemini-2.0-flash-thinking-exp-01-21 LLM solves the 2024 contest puzzles, using a variety of popular programming languages: C, C#, C++, Clojure, Common Lisp, Dart, F#, Go, Haskell, Java, JavaScript, Kotlin, Lua, Objective-C, OCaml, Perl, PHP, Python, Ruby, Rust, Smalltalk, Swift, TypeScript, and Zig.
I developed a prompt was developed to guide the model in a multi-turn conversation. The model was given 5 conversational turns to produce a correct puzzle solution.
Results: Depending on the programming language used, the model was capable of solving from a high of 69% to a low of 8% of the puzzles.
The Gemini model optionally supports code execution of Python programs. Enabling code execution results in poorer performance. The solve rate with no code execution: 69%, code execution of examples: 59%, code execution of examples and the actual puzzle input: 16%.
Here’s the full paper: Using a Gemini Thinking Model to Solve Advent of Code 2024 Puzzles in Multiple Programming Languages
27 Dec 2024
I recently used Gemini to help me participate in the 2024 Advent of Code
contest. Gemini 1206 was able to solve 60% of the 2024 puzzles
without any human assistance beyond the well designed puzzle specifications and
a carefully crafted prompt.
Two questions naturally arise:
- Gemini comes in several flavors. How do they compare in their ability to
solve Advent of Code puzzles?
- How well will Gemini do on older years of Advent of Code?
I wrote a suite of Python programs to help me answer those questions.
As you probably guessed, I used Gemini to help me wrote these programs.
I wrote a detailed spec for a program that would:
- Maintain a database of which puzzles had been solved by which model.
- Pick which puzzle to solve next, using which model.
- Use the model to generate a program to solve the puzzle.
- Run the program.
- Compare the program’s output to the correct answer, and update the puzzle
database.
- Run a web server to show the results as a web page.
- Have the ability to generate reports as markdown or csv.
- Have the ability to perform simple database edits. For example, to remove
puzzle test results when they need to be regenerated.
I constrained the design by requiring that:
- The programs must be written in Python.
- The test results must be stored in a SQLite3 database
- The web server must use the Flask framework.
- I provided a library with API functions to:
- scrape puzzle descriptions
- asking Gemini models to generate programs using the puzzle descriptions
- run the generated programs to produce an answer
- ask the AdventOfCode website to verify the answers.
- I used the excellent Advent of Code Data
package to scrape the puzzle descriptions and verify the answers. AOCD
implements local caching of descriptions and answers, so I didn’t have
to implement that feature myself.
The process of implementing the program proceeded iteratively:
- Write a detailed spec.
- Paste the spec into AI Studio.
- Paste the code into a Visual Studio Code project.
- Debug the code under the Visual Studio Code Python Debugger.
- Report errors and incorrect behavior to Gemini.
- Update code as suggested by Gemini.
- Sometimes I’d decide that I wanted to take another approach. To do that, I
would update my detailed spec and go back to step 2. Because the spec
specified the library API, I was able to reuse the library code with
different versions of the generated code.
The biggest stumbling block for development was the limited AI Studio free
quota for API access. 1500 API requests per day doesn’t go as far as I might
wish.
It took several rounds of experimentation and spec rewriting to settle on a
good design. I initially specified a single program to cover all the features.
But due to limitations of Unix forking, it turned out to work better to have
four separate programs, one for each feature, all communicating through a common
SQLite database.
Gemini’s generated code was good. There were many minor mistakes, but most of
them were easy to fix by pasting the error message and stack crawl into Gemini.
Gemini would explain what it thought the error was, and would almost always
produce a working bug fix.
When Gemini ran into a dead end, and progress stalled, I would move forward by
rethinking my design. Then I would update my design and regenerate the code.
The next time I do a project like this, I think I will try asking Gemini for
help with my design document.
It will probably take another few days to complete the project, but I think
from now on it’s mostly a matter of waiting for quota to regenerate, followed
by some statistic analysis of the collected data.
Some interesting potential follow-up projects:
- Feeding puzzle solution code errors back to the models, to see if that
improves their performance. It seems likely that this would help, since
Gemini sometimes makes simple mistakes that it can easily fix if shown
the resulting error message.
- Trying other models like Claude and OpenAI. (Limited by limited free quota.)
- Trying open source models like Llama. Limited by my slow personal hardware.
- Using languages other than Python for the test harness code.
- Using languages other than Python for the puzzle code.
24 Dec 2024
This year I used the Gemini 1206 LLM to participate in the Advent of Code contest. The LLM was able to solve 60% of puzzles just from the description, and an additional 15% of the problems with simple assistance.
| Result |
Percent |
| Solved puzzle without human interaction |
60% |
| Solved puzzle with simple debugging |
75% |
| Solved puzzle when given strong hint |
90% |
| Failed to solve puzzle |
10% |
| Category |
Count |
Zero-shot |
With assistance |
With hint |
Failed |
| Part 1 |
25 |
18 |
4 |
2 |
1 |
| Part 2 |
24 |
11 |
4 |
5 |
4 |
| Total |
49 |
29 |
8 |
7 |
5 |
The day-by-day solutions can be found in this Github project: github.com/jackpal/aoc2024
Disclosures and background
I work as a SDE at Google, but I don’t work in ML or on the Gemini project. I’ve competed in Advent of Code since 2020, and have gone back and solved all of the problems, often using hints from r/adventofcode and other web discussions. I’ve been interested in LLMs and other machine learning / AI since my student days at MIT, where I caught the tail end of the original AI wave.
Experiment setup
I decided to start using a LLM on Day 11 of the contest. In order to avoid polluting the leader board, I waited 10 minutes after the start of each day’s contest to begin working on that day’s problem. This kept my LLM-assisted scores off the leaderboards. I also went back and solved the earlier days’ problems. Since those earlier day problems were submitted more than 24 hours after the problem was announced, they didn’t affect the leaderboard scoring.
I used Google’s AI Studio, with a custom system prompt. I used the default temperature setting 1.0.
For each day I:
- Manually visited the Advent of Code puzzle page using a Chrome browser.
- Copied the “part one” text of the puzzle, including examples.
- Pasted that text into the “Type something” box of AI Studio.
- Pressed “Run”
- Copied the generated Python code from AI Studio
- Pasted it into a Jupyter notebook running on Visual Studio Code and Python 3.13.1. I had the aocd and networkx libraries installed in the Python environment.
- Ran the Python code.
- If there were issues, I would debug them, potentially prompting the LLM to try again.
- Once Part 1 was complete, I would repeat the steps with “Part Two” of the puzzle.
Automating the process
I used the “Advent of Code Data” Python library to automate retrieving the puzzle input and submitting the puzzle answers. I experimented briefly with automating the process of using the LLM. I was able to automate steps 1-5, but didn’t automate running and scoring the generated Python code. Automating the process would be helpful for comparing the effects of different prompts, as well as comparing the quality of different models.
Mistakes
I accidentally submitted my solutions early on Day 23, getting 8th place on the part 1 and 135th place on part 2. Sorry, humans!
Comparing different versions of Gemini
During the experiment I tried several different versions of Gemini that were available on AI Studio:
- Gemini 2.0 Flash Experimental
- Gemini Experimental 1206
- Gemini 2.0 Flash Thinking Experimental
As far as I can tell, Gemini Experimental 1206 gave the best results for Advent of Code. I only
found one case, Day 25, where Gemini 2.0 Flash Thinking Experimental
scored better than Gemini Experimental 1206.
That being said, the other models were capable of solving the simpler/easier
problems. It would be interesting to study the relative strengths of the
different models.
I very briefly experimented with non-Gemini models, including LLama 3.3 70B and
whatever version of OpenAI Microsoft Bing was serving on December 10th. But in
my limited testing, they were not obviously superior to Gemini 1206, so I decided to concentrate on Gemini 1206. It would be interesting to run the experiment on a variety of other models.
Prompt Engineering
After experimenting with small tweaks during the contest, my System Instruction prompt was a variation of:
You are an expert Python coder. You are participating in the "Advent of Code" programming contest. The following is a puzzle description. Write expert Python code to solve the puzzle.
The puzzle has two parts. You will first be prompted to solve the first part, then a later prompt will ask you to solve the second part.
First write a short explanation of the algorithm . Then write the code.
Read the puzzle input in the form of a text string from puzzle.input_data. Assign the puzzle answer to the property puzzle.answer_a for the first part. Assign the puzzle answer to puzzle.answer_b for the second part.
Only assign to puzzle.answer_a one time. Don't use puzzle.answer_a as a temporary variable or an accumulator.
For example if the puzzle is, "The input is a series of numbers, one per line. Calculate the sum of the numbers", then the code you generate could look like this:
def solve_a(input_data):
return sum([int(line) for line in input_data.splitlines()])
puzzle.answer_a = solve_a(puzzle.input_data)
And if the "Part b" of the puzzle is "Calculate the product of the numbers instead", then the code you generate could look like this:
def solve_b(input_data):
return prod([int(line) for line in input_data.splitlines()])
puzzle.answer_b = solve_b(puzzle.input_data)
Assume that the input is valid. Do not validate the input.
Think carefully. It is important to get the correct answer and for the program to run quickly.
Use split('\n\n') to split chunks of the input that are separated by blank lines.
Pay attention to whitespace in the input. You may need to use "strip()" to remove whitespace.
Use @cache for recursive functions that are called frequently with the same parameters.
If the problem is a graph or network problem, use the networkx library to solve it.
Use subroutines, lambdas, list comprehensions and logical boolean operators where it will make the code shorter.
Use short function names and short variable names.
Assume this code has already been executed to get the puzzle object set up:
from aocd.models import Puzzle
from pathlib import Path
puzzle = Puzzle(year=2024, day=int(Path(__vsc_ipynb_file__).stem))
Gemini did not always adhere to this prompt. Sometimes it generated verbose code.
Prefer short code
It takes Gemini significantly more time to generate code with long variable names and comments than it does to generate short code without comments. For Advent of Code puzzles it’s often clearer to use short variable names, so that more of the algorithm can fit on screen. And in any timed competition it’s better to get the answer generated sooner rather than later.
Asking Gemini to generate a description of the algorithm it is using was helpful in two ways:
-
It may have lead to better code, due to giving the LLM more time to “think” about the problem. (Not certain of this, but it is true of other code LLMs.)
-
It helped me understand the code, which was helpful when debugging the code.
Avoid trying to cover every possible case in the system prompt
I found it was better to keep the system prompt relatively short, especially with respect to advice that was only applicable in some situations. For example, I experimented with adding the direction “be sure to handle very large inputs” to the prompt. While this was helpful for some problems, it caused more problems than it solved, because it pushed the LLM towards less common data structures, which caused it to make more mistakes.
I found that it was better to keep the prompt short, and add “be sure to handle very large inputs”, or “that’s too slow” follow-up prompts as needed.
Results
I started using Gemini on day 10. For the purposes of this report, I went back and used the LLM to solve the earlier problems as well. Here are my day-by-day notes on how successful I was. I score the LLM performance on a scale:
| Rating |
Meaning |
| 0 |
LLM did not produce a working solution, even when prompted with a hint that explained how to solve the problem. |
| 1 |
LLM produced a working solution after being prompted with a hint that explained how to solve the problem. |
| 2-3 |
LLM required help to debug mistakes in its code (such as off-by-one errors or coordinate system errors.) Score a 2 if the mistake is difficult to debug, 3 if the mistake is easy to debug. |
| 4 |
LLM produced a working solution after being prompted with simple prompts like “make it run faster”. |
| 5 |
LLM produced a working solution, no additional prompts required. |
Gemini 1206 performance
| Day |
Part 1 |
Part 2 |
Notes |
| 1 |
5 |
5 |
|
| 2 |
5 |
5 |
|
| 3 |
5 |
5 |
|
| 4 |
5 |
5 |
Some versions of system prompt had problems generating code for part 2. |
| 5 |
5 |
5 |
|
| 6 |
5 |
2 |
Faulty “guard against infinite loop code” in part 2. |
| 7 |
5 |
5 |
|
| 8 |
5 |
5 |
|
| 9 |
5 |
5 |
|
| 10 |
5 |
5 |
|
| 11 |
5 |
2 |
Prompt for part 2: That’s still too slow. Can you think of a different way of counting the stones? |
| 12 |
5 |
1 |
Had trouble counting edges correctly. Had to be prompted with corner-counting algorithm. |
| 13 |
5 |
1 |
Use Cramer’s Rule |
| 14 |
5 |
1 |
See Day 14 Easter egg prompt below |
| 15 |
1 |
0 |
Part 1 prompt: You have to recursively check-and-move the boxes. No known working prompt chain for part 2. |
| 16 |
5 |
1 |
See Day 16 part 2 prompt |
| 17 |
2 |
0 |
See Day 17 part 2 for details. |
| 18 |
5 |
5 |
|
| 19 |
3 |
3 |
Mistakes parsing input. |
| 20 |
1 |
1 |
Succeeds with Reddit prompt |
| 21 |
0 |
0 |
Unable to code Reddit hints correctly |
| 22 |
5 |
2 |
Part 2 required prompts to optimize runtime and manual debugging of generated code. |
| 23 |
5 |
5 |
Day 23: LAN Party Part 1 and 2 both used networkx algorithms |
| 24 |
3 |
0 |
Day 24: Crossed Wires |
| 25 |
2 |
n/a |
Day 25: Code Chronicle |
Interesting Days
Day 14 Easter egg prompt
Day 14 was an unusual Advent of Code Puzzle. The part 2 directions did not provide a way of detecting a Christmas tree. The LLM was completely lost.
Once this hint was provided, the LLM produced code that worked well:
That's not correct. Run the simulation normally, but each step, calculate the number of horizontally or vertically adjacent robots. Two robots are horizontally adjacent if their x coordinates differ by 1 and their y coordinates are equal. Two robots are vertically adjacent if their y coordinates differ by 1 and their x coordinates are equal. Keep track of the maximum number of adjacent robots seen. Simulate 10000 steps and then print the step number that had the maximum number of adjacent robots.
I’m using the agreed upon scoring rubric, but it could be argued that this response should be scored more highly, because the puzzle directions were intentionally obscure.
Day 15 part 2
Nothing worked. Lots of incorrect code generated. The LLM had trouble maintaining the data structures for the wide-box simulation, even when prompted with the specific answers.
Day 16 part 2 prompt
Used this prompt, which is a lightly edited version of a Reddit comment
That's not correct. Here is a hint: Run a Dijkstra to get the distance matrix (from_start).
Obtain from_end by running another Dijkstra, but with 4 starting vertices [ (target_row, target_col, dir) for dir in "EWNS"]
Iter through every coord and direction and check if from_start[(row,col,dir)] + from_end[(row,col,flip(dir)]) is the same as answer from part 1.
Day 17 part 2
To solve day 17 part 2 you had to analyze your specific input program, reverse engineer it, and then write a search function that searched a narrow, deep, tree.
The LLM made mistakes on both part 1 and part. It was unable to provide a useful program for part 2. But it was able to generate correct subroutines when directed to by special-purpose prompts. For example I asked it to disassemble my puzzle input, turning it into Python code, and it did a fairly good job, making just one mistake. Similarly, when I asked it to write a search function, it wrote one quickly.
Day 19 whitespace parsing
Both parts had problems parsing the puzzle input. Items were separated by
‘, ‘, but the LLM split on ‘,’ instead of the correct ‘, ‘.
Day 20: Race Condition
No luck with LLM or on my own. LLM solved easily with this Reddit-provided hint:
Both parts 1 and 2 can be solved using the same algorithm. Write a single function solve(allowed_cheat_length) that is used for both solutions.
We find the distance from end position to any other position.
We find the path from start to end using knowledge of the distance from any point to end
For each pair (a,b) where a and b are some coordinates of the fastest path
calculate Manhattan distance between a and b
if this distance larger than allowed cheat, a -> b is not an allowed cheat
if the distance from b to the end + distance from a to b is not lower than the distance from a to b, then there is no benefit of such "cheat"
if the benefit of the move from a to b is less than defined minimal benefit - we ignore it
otherwise, increase counter of valid cheats by 1
Day 21: Keypad Conundrum
This was a rough day for the LLM. It was unable to implementing the optimal algorithm, even with numerous Reddit hints.
The LLM handled parsing the input and creating an overall program structure, but was unable to think of the necessary optimizations.
Day 23: LAN Party
The LLM correctly identified that the problem could be solved by finding cliques. But the code it generated for finding cliques was buggy. Amending the system prompt to recommend using the networkx library for network and graph puzzles solved this problem because the LLM was able to call the bug-free networkx clique algorithm.
Day 24: Crossed Wires
The LLM was helpful for solving part 1. For part 2, it couldn’t help with a
simple solution, but it was helpful for utility functions, visualizers,
stats computations, and also as a reference, for example it correctly
answered “what is the circuit for a full adder”.
In the end I had the LLM write a sum(x,y) function, and used it to help identify bits that were bad. An undocumented simplifying feature of the actual input data was that the swapped circuits were always within
a single full adder. So it was easy enough to identify the four full adders in my input that had bad bits, and then inspect the 5 gates per full adder to see which two gates had their outputs swapped.
Day 25: Code Chronicle
Gemini 1206 misunderstood how to parse the input, and how to tell locks from keys. It also had several off-by-one errors in the tumbler/key height calculations. It required four rounds of prompt correction to produce the correct answer.
Gemini 2.0 Flash Thinking Experimental also misunderstood how to parse the input, but otherwise made fewer mistakes than Gemini 1206. It only required one prompt correction (explaining how to parse the input) in order to produce the correct answer.
Uses beyond solving puzzles
Gemini 1206 is good for more than just trying to solve the puzzle:
- Parsing. Gemini does a pretty good job of parsing puzzle input. I did run into two flaws:
-
Gemini needs help parsing input that uses blank lines to separate different chunks of input. I had to explicitly instruct it, “Use split(‘\n\n’) to parse chunks separated by blank lines.
-
Gemini is blind to whitespace following commas, so it doesn’t parse “a, b” correctly. It uses split(‘,’) instead of split(‘, ‘). I wasn’t able to discover a prompt to fix this. The best I figured out was to either manually correct the issue, or to ask it to strip() the resulting parts.
-
Debugging. I was stuck helping my friend debug their code for Day 16 Part 1. His code solved the examples, but not his input. We worked on the code for 30 minutes, rewriting almost all of it. But nothing helped. Finally, we dumped his original code into Gemini and asked Gemini to find the bug. It immediately pointed out the bug (a direction table with a copy-and-paste error).
-
Visualization. Several days I asked Gemini to add a visualization to my code. (For example, showing a path on a grid.) It was simple code, but Gemini wrote it more quickly than I could have.
- Other languages besides Python. I didn’t experiment much with this. I did see that Gemini was able to produce working Go code. I expect it would work for other popular languages as well.
Conclusions
In many ways Advent of Code is a “best case scenario” for LLM-based code generation: The problem descriptions are extremely clear. The two parts of each problem help the LLM refine its understanding of the problem space. The problems are typically solved by applying well known computer science algorithms. The problems are designed to be solved by normal programmers, using normal Python, after a modest amount of thinking time and computer time. There are 441 published example problems, with hundreds of solutions for each problem are available on the web.
I found it enjoyable to use the LLM for help with the harder puzzles. Even when it couldn’t solve the puzzle, the LLM helped me with parsing, visualization, and utility functions. It also sometimes helped with debugging and with answering general knowledge questions.
This was my first experience using LLMs to generate code. I was impressed by the results and I look forward to trying LLMs in other problem domains.
I think I will continue to use LLMs in future Advent of Code competitions. I’ll keep my “wait at least 10 minutes” personal rule in place, to give unassisted humans a sporting chance. I wish there was a separate LLM-assist leader board, that would be fun to compete on.
03 Nov 2024
Here’s my opinion about the quality of English-language tech discussion on the Internet.
| Service |
Quality |
Tech communities |
| Blogs |
3 |
Everything, but author population is older. |
| Bluesky |
4 |
Nothing |
| Commercial Web |
3 |
Android, iOS, Mac, PC |
| Forums |
3 |
Tends to older, PC-centric tech, so web, PC. |
| Mastodon |
3 |
Limited iOS, Limited Open Source |
| Newsletters |
4 |
Business |
| Podcasts |
3 |
iOS, tech news |
| Threads |
4 |
Limited, Meta centric. |
| Twitter (X) |
3 |
Everything, especially iOS, Graphics, and ML |
| YouTube |
4 |
Android, iOS, PC, ML |
Not listed, but also a source of tech discussion, are broadcast TV, magazines, and books.
I also hear that there’s tech discussion on Instagram, Snap, TikTok and Twitch, but I haven’t tried them.
The net net is that my best tech information comes from:
- Ruthlesly curated topic lists on x.
- Newsletters by Matt Gurman, Matt Levine, Benedict Evans and Ben Thompson.
- Forums like Hacker News and Reddit.
- Commercial tech news sites like techmeme and The Verge.
- Tech YouTubes like MKBHD, and Joanna Stern
- Tech podcasts like Accidental Tech Podcast and Macbreak Weekly.
X is in a downward spiral. But it is still the best site for tech news, especially in fast-moving fields like Machine Learning. I keep my X experience sane by:
- using the web interface with an ad blocker.
- using hand-curated lists
- blocking off-topic posters
- muting all words and phrases related to politics.
It would be nice if the tech communities that are currently on X moved to other services, but so far that doesn’t seem to be happening. The vibrant iOS community that used to meet on X was greatly weakened when it split between X, Bluesky and Mastodon. Now no site has critical mass, and iOS discussions are suffering.
I enjoy the non-X sites that I have tried. They each have their niche communities. They generally have much better UX than X. And they are less toxic than X. Unfortunately none of these other sites have developed significant tech communities for the topics I follow.
27 Jul 2024
I recently needed to search through a collection of 20,000 text files. After trying basic tools like find and grep, I decided to give sqlite3 a try.
Data Preparation
Using a Jupyter Notebook, I cleaned the documents and imported them into a sqlite3 database. I used Beautiful Soup to extract text from both HTML and plain text documents. The
entire cleaning process took around 5 hours. Once I had everything figured out, the actual database import step took about 30 seconds.
Full Text Search with FTS5
I created an FTS5 virtual table to enable fast full-text search with boolean logic and fuzzy matching. This allowed me to quickly find relevant
files.
I wrote a second Jupyter Notebook to provide a simple notebook cell based UI for querying and retrieving documents. That worked, but I wanted to make things even more convenient.
Web-Based Search UI with Flask
I built a simple web-based search UI using Flask. To create and debug the Flask server, I used Visual
Studio Code with their excellent Flask tutorial.
Lessons Learned
- Jupyter Notebooks are a useful tool for data cleaning and import.
- sqlite and FTS5 works well for simple document search applications.
- Flask is an easy-to-use library for simple web servers.
- Visual Studio Code is great for creating and debugging Flask servers.
Room for Improvement
- The UI could be improved by using a design system like Bootstrap.
Overall, I was able to create a functional search tool that can handle a my collection of text files. It took about 10 hours of work, and I learned a few things along the way.
Two thumbs up, would hack again!
06 Jul 2024
I tried out the Concordia LLM-driven agent framework.
I ran it on my own macbook, using ollama to serve a variety of LLMs. I used Visual Studio Code to run the Concordia example notebooks. I used venv to manage the Python virtual environment.
To adapt the notebook to run Ollama, I first used ollama pull <model-name> to install each model locally, then I changed
from concordia.language_model import gpt_model
model = gpt_model.GptLanguageModel(api_key=GPT_API_KEY,
model_name=GPT_MODEL_NAME)
to
from concordia.language_model import ollama_model
model = ollama_model.OllamaLanguageModel(model_name=OLLAMA_MODEL_NAME)
I tried gemma2:9b, gemma2:27b, and mixtral:8x7b.
gemma2:9b worked, but had trouble adhering to the prompts.
gemma2:27b is currently broken in Ollama 0.1.48, it doesn’t stay on topic. Supposedly will be fixed in 0.1.50.
Mixtral ran too slowly to be useful.
I didn’t get a good result, but I think if I kept trying with different models I might find a good result.
Overall the concept seems promising. It’s kind of the authors to make their toolkit available!