24 Dec 2015
Just an update on my family IT use.
The T-Mobile family plan has worked great for us. T-Mobile’s plans are nice
for us because:
- The third, fourth, and fifth lines are only $10 / month.
- When the paid-for data is exhausted, the plans automatically switch over to unlimited free low-speed data for the rest of the month.
- Streaming music doesn’t count against the data caps.
- Free phone calls, texts, and low-speed data in Canada and Taiwan. (It was great using Google Maps to get around Vancouver. I was using many short cuts that I didn’t know about when I was navigating using paper maps.)
- For the last 3 months of 2015 T-Mobile had a special where they gave everyone unlimited high-speed data for free.
I ended up getting used iPhone 5s’s for all my kids. I had the kids pick their own otterbox commuter cases.
My son was initially frustrated at having to give up his rooted and customized
Android phone for the smaller, less customizable iPhone. He’s grown used to
it, and likes it now. Everyone loves the fingerprint unlocking feature of the
5s.
I have the phones set up with restrictions, so that the kids can’t install
their own apps. I also confiscate-and-recharge their phones and laptops each
night. This is fairly foolproof, and gives the kids 8 hours a day to sleep
without electronic distractions.
I bought an Anker 6-port USB charger for my bedside table. I use it to
recharge everyone’s phones while keeping an eye on them. I have the phones on
“Do Not Disturb” mode, so they don’t bother me over night.
The “Find my Friends” app has proved helpful for keeping track of where
everyone is, especially for things like picking kids up at school and at bus
stops.
We now have 5 laptops: four 13” Macbook Airs and one 13” Macbook Pro. They
work great and last a long time. They are mostly used for web surfing, YouTube
and Minecraft.
We have had problems with headphones – the kids are rough on headphone
cables. They’ve already gone through one set of headphones each. Currently
we’re using Beats headphones due to them being relatively cheap on sale and/or
included in Apple Educational bundles. They look stylish and work OK. Apple
has a fairly good warranty repair process for their Beats headphones.
26 Jul 2015
A few products that made my summer family travels happier:
Photive 6 port Desktop USB Charger.
Anker 4-port USB car cigaret lighter charger.
Car vent phone holder (don’t remember the brand.)
Short stereo audio cable. It’s ghetto compared to bluetooth, but more
reliable.
26 Jul 2015
As summer draws to a close, I am planning my family’s computer use for the
2015-2016 school year.
My plans for this year are:
- Each family member gets their own mobile phone and laptop.
- We also have a shared desktop and a few shared tablets.
- Shared network scanner/laser printer.
- We print color documents and pictures at the library or at the drugstore.
- Android TV for shared movie watching.
- Chromecast for audio sharing.
- Comcast Business Internet
- Apple Time Capsule for backup / WiFi / NAT
Note the lack of a dedicated game console. The kids play games on mobile,
tablets, and laptops (for Minecraft specifically!).
My two youngest kids are getting their first phones this year. I’m worried
about their phones getting lost, broken, or stolen. So for the first six
months my kids will use hand-me-down phones. After they’ve learned to take
care of phones, I’m going to give them better phones. (Still used, though!)
To achieve my plan I need to buy one laptop and three mobile phones. For the
laptop I’m leaning towards a 13” Retina Macbook Pro. For the phones I’m
leaning towards used iPhone 5Ss.
Why a Macbook and not a Chromebook? Build quality and applications. I have a
low-end ARM Chromebook, and I noticed that nobody in the family uses it by
choice, due to its low speed and poor quality screen. I could get a
Chromebook Pixel, but for my family, at that price level a Macbook is a better
deal.
Why iOS and not Android? It comes down to ease-of-administration. I want to
lock down my kids’ phones, and unfortunately experience with my oldest child
using Android is that it’s all-too-easy for him to defeat the aftermarket
Android parental control apps.
For phone service I’m probably going to go with the BYOD T-Mobile Family Plan,
because:
- It is cheap.
- Unmetered music streaming.
- When you hit your data cap it switches to low speed data for the rest of the month, rather than charging more.
- It has free 2G international roaming.
Thoughts on laptops and other legacy hardware
If I were on a tighter budget, or starting from scratch, I’d consider dropping
the laptops, the Comcast Internet, and the home WiFi, and going pure mobile. I
would get bluetooth keyboards to make typing school assignments easier.
26 Jul 2015
Story of my hobby hacking life these days:
- Think of an idea for a small application to write to learn a new technology and incidentally make my life better.
- Prototype the app.
- Plan a MVP, estimate costs in time and money to develop.
- Search Play Market and/or IOS App Store, find that reasonable equivalent already exists, and is only $2.
- Buy the existing app, get on with life.
This happened to me last week with the concept of a “comic book reader”. I
wrote a prototype that let me browse my collection. I was starting to list out
all the features I needed to add (zooming, panning, sorting,RAR archive
support…). And then I did a web search for comic book reader, spent a couple
of minutes reading reviews, and bought one of the popular ones for $2. Sure
it’s got UI issues, and bugs, and doesn’t quite work like it should, but I
saved myself weeks of development time.
I need to think through how best to spend my hacking time in today’s world of
super abundance. What’s my
comparative advantage in this new
world? What’s my
compliment?
What am I trying to learn, trying to achieve? What is worth working on?
Existential questions on a Sunday morning. :-)
26 Jul 2015
Pixar released their Non Commercial version of Renderman. Woo! Hurray for
patent expiration dates!
If you don’t have Maya and you do have Mac and you just want to play with the
command-line version, you have to jump through several hoops:
You need to install XQuartz before trying to
install Renderman. (Otherwise the Renderman installer will fail.)
You need to copy /Applications/Pixar/RenderManProServer-19.0/etc/rendermn.ini
to ~/.rendermn.ini (Note the added “.” in the front.)
You need to edit .rendermn.ini to add the line
/licenseserver ${RMANTREE}/../pixar.license
You need to add these lines to your bashrc (or equivalent, depending on your
shell.)
(Found on https://www.fxphd.com/kbslug/renderman/)
export RMANTREE=/Applications/Pixar/RenderManProServer-19.0/
export DYLD_LIBRARY_PATH=/Applications/Pixar/RenderManProServer-19.0/lib/
export RMANFB=it
export export
PATH=$PATH:$RMANTREE/bin:$RMSTREE/bin/it.app/Contents/MacOS:$RMSTREE/bin/slim.app/Contents/MacOS
Once you’ve done that, you can use the “prman” command line tool to render rib
files.

15 Apr 2015
I am shutting down “Terminal Emulator for Android”
development again.
Why am I doing this?
- I have lost interest in the core idea of an on-device terminal emulator.
- Maintaining project, even in its mostly stable state, is taking up too much of my time.
- I do not want to give control of the app to other developers, for fear that they will ruin the app by adding bugs, ads, in-app purchases, or malware.
What this means:
- I will make one or two more releases based on the current source tree. (Which has a few small bug fixes.)
- I will be closing all open bugs as “won’t fix”.
- I will be rejecting all future pull requests.
What you should do:
- If you’re a user, the app will continue to be available in its current state.
- If you’re a developer, you are welcome to fork the app to start your own version. Maybe get together with other developers and make something great!
27 Mar 2015
As seen on Hacker News:
Hacker News Comment by dmbaggett
Maybe Andy forgot to mention it; it’s been a while since I’ve read the whole
series.
The code was C and lisp so it didn’t really require any effort to port other
than replacing the rendering pipeline. And we used the SGIs to pre-render
every frame anyway, to precompute the polygon sort order. (The PS1 had no
Z-buffer, so you were stuck sorting polygons at run-time if you didn’t do
something clever.)
So we already had the rendering pipeline ported. Obviously you couldn’t save
your game to the memory card, etc. – some stuff didn’t work. But the game was
playable (albeit very frustrating with keyboard controls).
Some day I will write this up for real, but without going into detail, here’s
a summary.
The camera in Crash was on a rail. It could rotate left, right, up, and down
(in Crash 2 and beyond, at least), but could not translate except by moving
forward/backward on the rail. This motivates a key insight: if you’re only
rotating the camera, the sort order of the polygons in the scene cannot
change.
This allowed us to sample points on the rail and render the frame at each
sample point ahead of time, as a batch job, on the SGI using a Z-buffer. (We
may have done the Z-buffer with software; I don’t remember.) Then we could
recover the polygon order of each frame by looking at the Z-buffer. And, even
better, at run-time we could simply not render at all those polygons that
weren’t ultimately visible in the pre-rendered scene. This solved both the
sorting and clipping problem nicely, and made the look of the game closer to
3K polygons/frame vs. the 1K polygons we were actually rendering in real time.
(Many polygons were occluded by other polygons.)
The trick, though, was what exactly to do with this sort/occlusion
information. In a nutshell, what I did was write a custom delta-compression
algorithm tailored to the purpose of maintaining the sorted polygon list from
frame to frame, in R3000 assembly language. Miraculously, this ended up being
quite feasible because the delta between frames was in practice very small –
a hundred bytes or so was typical. And if a transition was too heavyweight
(i.e., the delta was too big) we’d either sample more finely in that area or
tell the artists to take stuff out. :)
One thing nobody talks about but which is obvious in retrospect is that
without a Z-buffer you’re pretty screwed: sorting polygons is not O(N lg
N) – it’s O(N^2). This is because polygons don’t obey the transitivity
property, because you can have cyclic overlap. (I.e., A > B and B > C does
not imply A > C). This is why virtually every game from that era has
flickery polygons – they were using bucket sorting, which has the advantage
of being linear time complexity, but the disadvantage of being wrong, and
producing this flickery effect as polygons jump from bucket to bucket between
frames.
I’ll leave the matter of weaving the foreground characters – Crash himself
and the other creatures – into the pre-sorted background for another day.
13 Feb 2015
Run a Minecraft Server on OSX Boot2Docker
Here’s how I did it. I hope you find it useful!
One-time Setup
Do these steps once, to initialize Boot2Docker:
Step 1: Install Docker for OS X
Step 2: Create a directory to hold your Minecraft files. This needs to be
under the /Users part of your file system because boot2docker automatically
mounts /Users to the boot2docker-vm.
mkdir /Users/yourname/minecraft/data
Step 3: Initialize boot2docker
boot2docker init
Step 4: Forward the TCP port Minecraft uses from the Mac to the boot2docker-vm.
VBoxManage modifyvm “boot2docker-vm” –natpf1 “tcp-port25565,tcp,,25565,,25565”;
Start Minecraft
Do these steps every time you want to start your Minecraft server.
Step 1: Start boot2docker.
boot2docker start
Step 2: Set up the shell variables so you can use the docker command.
$(boot2docker shellinit)
Step 3: Run the minecraft container.
CONTAINER=$(docker run -v /Users/yourname/minecraft/data:/data -d -e EULA=TRUE -e VERSION=LATEST -p 25565:25565 itzg/minecraft-server)
The first time your run this it will take a few minutes to download and
install minecraft. After that it should be much faster
View the Minecraft Server Log
docker logs $CONTAINER
This prints out the logs from the container (you set the CONTAINER variable as
part of the docker run command above.)
If you’ve lost track of your container, you can list all currently running
containers.
docker ps
If you don’t see any containers, you container may have already exited. The
Minecraft server will exit if it encounters an error while running.
Shut Down
You can shut down all running containers and quit boot2Docker by using the
stop command:
boot2docker stop
Note that the Minecraft Server files will be stored in
/Users/yourname/minecraft/data, and when you’ve stopped the server you can
edit the files using your mac. (You might want to edit the files in order to
modify the server settings.)
09 Feb 2015
I’ve been reading the book Masters of Doom
about the careers of John Carmack and John Romero. I have ported their games
Doom and Quake to many
different
platforms. It was interesting to read
about their lives and game business.
The book brought back memories of development in the ‘80’s, and ’90s. Things
were simpler (and worse) then.
Some other John & John links:
The Rise and Fall of Ion Storm
Stormy Weather
Carmack QuakeCon Keynotes
12 Jan 2015
I’ve long-since misplaced the source code to my Atari 800 game Dandy Dungeon.
But thanks to the Atari800MacX
emulator and the emulation scene, I’ve been able to play an emulated version
of my original game. That’s been helpful for remembering all the little
details of gameplay.
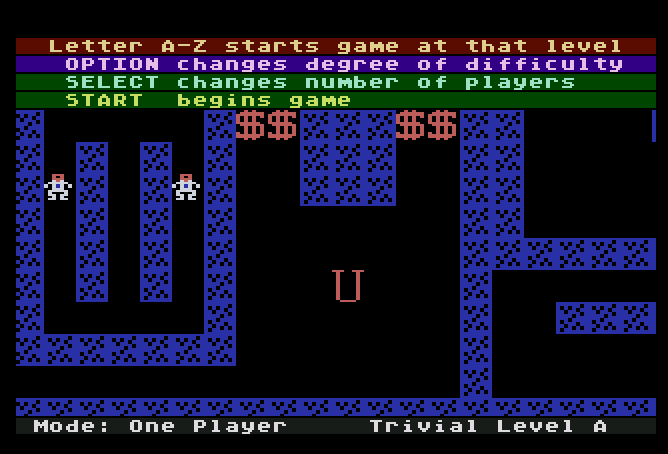
For example, I was able to determine that the original game animated the
arrows at 15 Hz and the players and monsters at 7.5 Hz.
FWIW I think the emulator may be slightly incorrect about the HBLANK
processing emulation. I’m pretty sure that the color background for the 4th
line of text should be a different color from the color background of the 3rd
line of text.
The iOS version of the game is progressing – the dual thumbstick virtual
controls work well.
The next step (and it’s a big one) is going to be multiplayer support. GameKit
here I come.